
Issue #5: LLMs with Vision
xAI previews first multimodal model, HuggingFace announces new 8B vision-language model

Welcome to Issue #5 of One Minute AI, your daily AI news companion. This issue will cover two announcements for multimodal models from xAI and Hugging Face.
 with vision capabilities. This scene shows a whimsical, robot-like figure with gentle, glowing eyes and a smile, symbolizing a welcoming presence. It stands in a bright, modern environment filled with colorful data streams and soft lighting. The robot has a smooth, rounded metallic body, emphasizing its approachable and non-threatening nature. It is actively engaged in processing visual data, represented by playful, animated graphics on nearby digital screens.")
xAI previews first multimodal model, Grok-1.5 Vision
Recently, Elon Musk’s xAI introduced its first multimodal model, Grok-1.5 Vision or Grok-1.5V. Grok-1.5V can not just evaluate text but also process a variety of visual information, including documents, diagrams, photographs, and more.
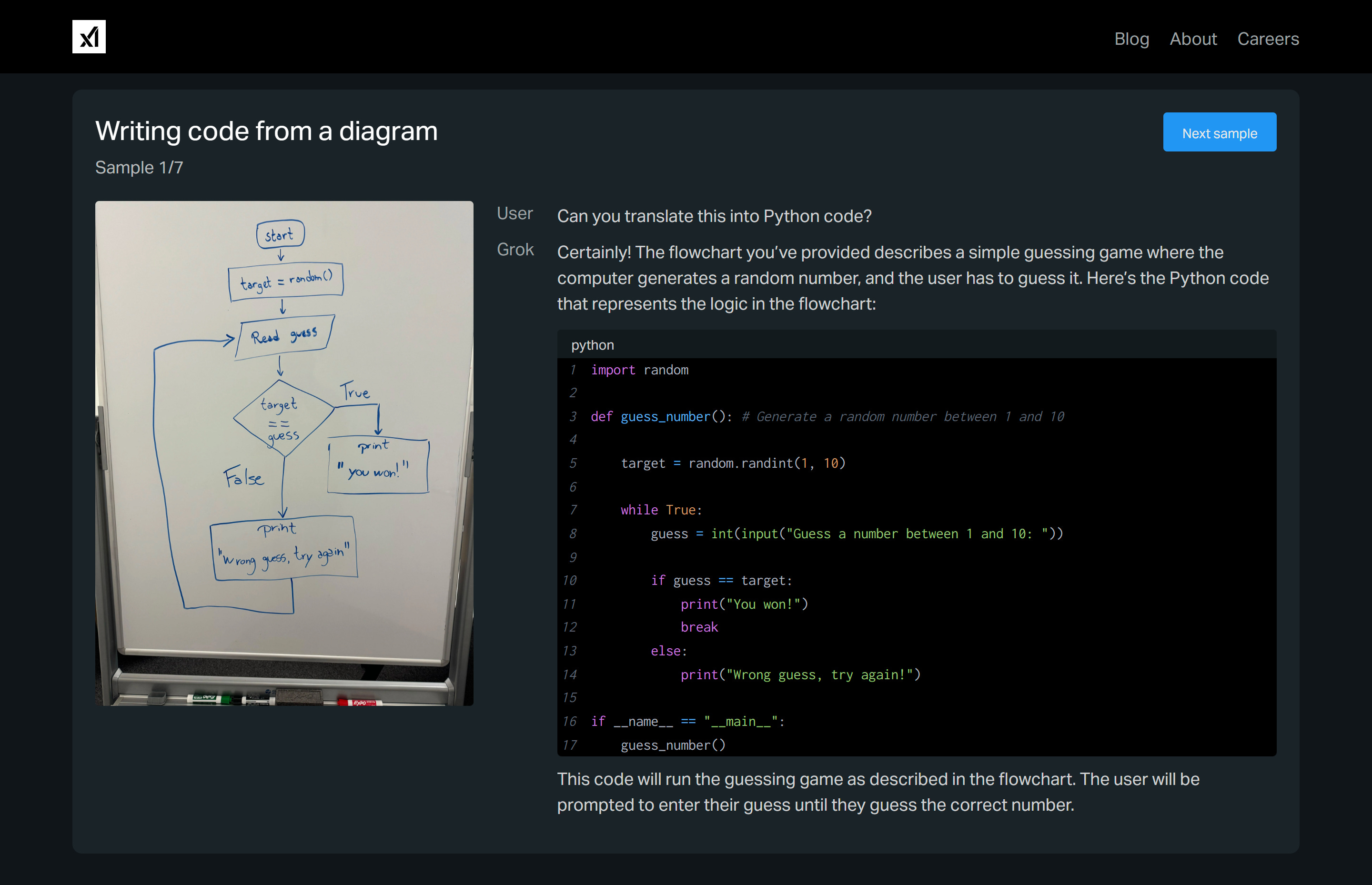
Grok-1.5V is competitive with existing frontier multimodal models in a number of domains, ranging from multi-disciplinary reasoning to understanding documents, science diagrams, charts, screenshots, and photographs. It also outperforms peers such as GPT-4V, Claude 3 Opus, and Gemini Pro 1.5 in their newly introduced RealWorldQA benchmark (to measure real-world spatial understanding).
HuggingFace announces new 8B vision-language model

Hugging Face has just announced a new general multimodal model, Idefics2, that generates text responses based on text and image-based input. It can answer questions about images, describe visual content, create stories grounded in multiple images, extract information from documents, and perform basic arithmetic operations.
Idefics2 performs exceptionally well on “Visual Question Answering” benchmarks and competes with larger models such as LLava-Next-34B and MM1-30B-chat.
Want to help?
If you liked this issue, help spread the word and share One Minute AI with your peers and community.
You can also share feedback with us, as well as news from the AI world that you’d like to see featured by joining our chat on Substack.
